최근에 Jetsetter의 대형 이미지 저장소로 복제를 가져 오지 않도록 중복 이미지 감지기를 구현했습니다. 이를 달성하기 위해 우리는 dHash 지각 해시 알고리즘과 멋진 BK- 트리 데이터 구조의 Python 구현을 작성했습니다.
Jetsetter는 수십만 개의 고해상도 여행 사진을 보유하고 있으며 매일 더 많은 사진을 추가하고 있습니다. 문제는 이러한 이미지가 다양한 출처에서 제공되며 반자동 방식으로 업로드되기 때문에 종종 중복되거나 거의 동일한 사진이 몰래 들어온다는 것입니다. 그리고 우리는 사진 검색 페이지가 속이는 것을 원하지 않습니다.
그래서 우리는 지각 해싱 알고리즘을 사용하여 중복을 필터링하는 작업을 자동화하기로 결정했습니다. 지각 해시는 훨씬 더 큰 데이터 조각의 작고 비교할 수있는 지문이라는 점에서 일반 해시와 같습니다. 그러나 일반적인 해싱 알고리즘과 달리 지각 해시의 아이디어는 원본 이미지가 가까우면 지각 해시가 “가까이”(또는 동일)하다는 것입니다.
차이 해시 (dHash)
우리는 Neal Krawetz가 사진 법의학에 대한 작업에서 개발 한 dHash ( “차이 해시”)라는 지각 이미지 해시를 사용합니다. 다음 단계 (128 비트 해시 값 생성)를 포함하는 매우 간단하지만 놀랍도록 효과적인 알고리즘입니다.
이미지를 회색조로 변환
회색 값의 9×9 제곱으로 축소 (또는 더 큰 512 비트 해시의 경우 17×17)
“행 해시”계산 : 각 행에 대해 왼쪽에서 오른쪽으로 이동하고 다음 회색 값이 이전 값보다 크거나 같으면 1 비트를 출력하고, 그보다 작 으면 0 비트를 출력합니다 (각 9 픽셀 행 8 비트 출력 생성)
“열 해시”계산 : 위와 동일하지만 각 열에 대해 위에서 아래로 이동
두 개의 64 비트 값을 함께 연결하여 최종 128 비트 해시를 얻습니다.
dHash는 매우 정확하고 이해하고 구현하기가 매우 간단하기 때문에 훌륭합니다. 계산도 빠릅니다 (Python은 비트 트위들 링에서 그다지 빠르지는 않지만 그레이 스케일로 변환하고 크기를 줄이는 모든 노력은 C 라이브러리 인 ImageMagick + wand 또는 PIL에서 수행됩니다).
이 프로세스가 시각적으로 어떻게 보이는지 다음과 같습니다. 원본 이미지로 시작 :

그레이 스케일 및 9×9로 축소 (하지만보기 위해 확대) :
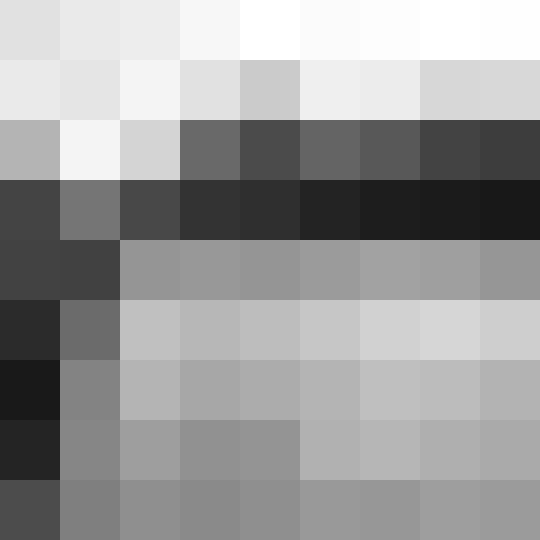
그리고 다시 확대 된 8×8 행 및 열 해시 (검정 = 0 비트, 흰색 = 1 비트) :
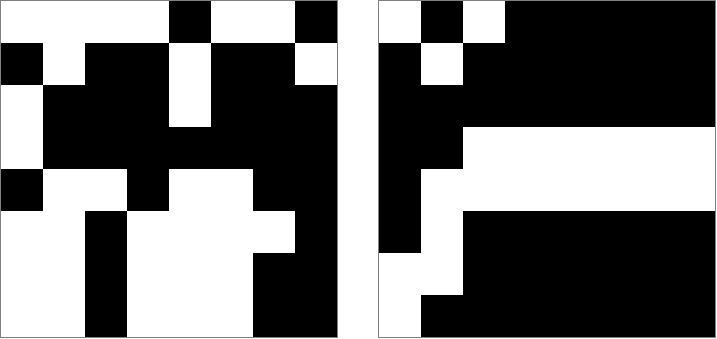
dHash 코드의 핵심은 몇 개의 중첩 for 루프만큼 간단합니다.
def dhash_row_col(image, size=8):
width = size + 1
grays = get_grays(image, width, width)
row_hash = 0
col_hash = 0
for y in range(size):
for x in range(size):
offset = y * width + x
row_bit = grays[offset] < grays[offset + 1]
row_hash = row_hash << 1 | row_bit
col_bit = grays[offset] < grays[offset + width]
col_hash = col_hash << 1 | col_bit
return (row_hash, col_hash)구현하기에 충분히 간단한 알고리즘이지만 몇 가지 까다로운 경우가 있습니다. 우리는 모두 함께 롤링하고 오픈 소스하는 것이 좋을 것이라고 생각했습니다. 따라서 Python 코드는 GitHub 및 Python Package Index에서 사용할 수 있습니다. 그래서 그것은 단지 pip 설치 dhash 밖에 없습니다.
중복 임계 값
이미지가 중복되었는지 확인하려면 해당 dHash 값을 비교합니다. 해시 값이 같으면 이미지가 거의 동일합니다. 해시 값이 몇 비트 만 다른 경우 이미지가 매우 유사하므로 두 값 (해밍 거리)간에 다른 비트 수를 계산 한 다음 주어진 임계 값 미만인지 확인합니다.
참고 : Python dhash 라이브러리에는 델타를 계산하는 get_num_bits_different ()라는 도우미 함수가 있습니다. 이상하게도 Python에서이를 수행하는 가장 빠른 방법은 값을 XOR하고, 결과를 이진 문자열로 변환하고, ‘1’문자 수를 세는 것입니다 (이는 C로 작성된 내장 함수를 요청하기 때문입니다. 노력과 반복) :
def get_num_bits_different(hash1, hash2):
return bin(hash1 ^ hash2).count('1')이미지 세트 (총 200,000 개 이상)에서 128 비트 dHash 임계 값을 2로 설정했습니다. 즉, 해시가 1 비트 또는 2 비트에서 같거나 다를 경우 중복으로 간주됩니다. 테스트에서 이것은 대부분의 속임수를 잡기에 충분한 델타입니다. 4 ~ 5 번 시도했을 때 지문은 비슷하지만 시각적으로 너무 다른 이미지 인 오탐 (false positive)을 포착하기 시작했습니다.
예를 들어, 이것은 2의 임계 값을 정하는 데 도움이되는 이미지 쌍 중 하나였습니다.이 두 이미지는 4 비트의 델타를가집니다.

MySQL 비트 카운팅
저는 PostgreSQL의 열렬한 팬이지만 이 프로젝트에 MySQL을 사용하고 있으며 PostgreSQL에없는 깔끔한 작은 기능 중 하나는 64 비트 정수에서 1 비트 수를 계산하는 BIT_COUNT입니다. 따라서 128 비트 해시를 두 부분으로 나누면 두 개의 BIT_COUNT () 호출을 사용하여 이진 해시 열이 주어진 해시의 n 비트 내에 있는지 여부를 확인할 수 있습니다.
MySQL은 이진 열의 일부를 64 비트 정수로 변환하는 방법이없는 것 같기 때문에 약간 우회적입니다. 그래서 우리는 16 진법으로 갔다가 반대로 변환했습니다 (더 나은 방법이 있는지 알려주세요! ). dHash 열은 dhash8이라고하며 dhash8_0 및 dhash8_1은 비교 대상 해시의 최고 및 최저 64 비트 리터럴 값입니다.
다음은 새 이미지를 업로드 할 때 중복을 감지하는 데 사용하는 쿼리입니다 (실제로 Python SQLAlchemy ORM을 사용하고 있지만 충분히 가깝습니다).
SELECT asset_id, dhash8
FROM assets
WHERE
BIT_COUNT(CAST(CONV(HEX(SUBSTRING(dhash8, 1, 8)), 16, 10)
AS UNSIGNED) ^ :dhash8_0) + -- high part
BIT_COUNT(CAST(CONV(HEX(SUBSTRING(dhash8, 9, 8)), 16, 10)
AS UNSIGNED) ^ :dhash8_1) -- plus low part
<= 2 -- less than threshold?위의 쿼리는 전체 테이블 스캔을 포함하는 비교적 느린 쿼리이지만 업로드시 한 번만 수행하므로 추가로 1 ~ 2 초가 걸리는 것은 큰 문제가 아닙니다.
BK- 트리 및 빠른 중복 감지
하지만 기존의 dupli를 검색 할 때
그러나 전체 이미지 세트 (당시 약 150,000 장)에서 기존 중복을 검색 할 때 O (N ^ 2) 문제로 빠르게 전환됩니다. 모든 사진에 대해 중복을 찾아야합니다. 다른 모든 사진. 수십만 개의 이미지를 사용하는 경우 너무 느려서 더 나은 것이 필요했습니다. BK- 트리를 입력하십시오.
BK- 트리는 “가까운”일치 항목을 빠르게 찾기 위해 특별히 설계된 n 진 트리 데이터 구조입니다. 예를 들어, 주어진 문자열의 특정 편집 거리 내에서 문자열을 찾습니다. 또는 우리의 경우 주어진 dHash의 특정 비트 거리 내에서 dHash 값을 찾습니다. 이것은 O (N) 문제를 O (log N) 문제에 더 가까운 것으로 바꿉니다.
2020 년 7 월 업데이트 : 실제로 O (log N)가 아니지만 거리 임계 값에 따라 log N과 N 사이에있는 다소 복잡한 거듭 제곱 법칙입니다. Maximilian Knespel의 자세한 분석을 참조하십시오.
BK- 트리는 Nick Johnson이 그의 “Damn Cool Algorithms”블로그 시리즈에서 설명합니다. 조밀 한 읽기이지만 BK- 트리 구조는 실제로 매우 간단합니다. 특히 여러 중첩 된 사전으로 트리를 만드는 것이 매우 쉬운 Python에서는 더욱 그렇습니다. 트리에 항목을 추가하는 BKTree.add () 코드 :
def add(self, item):
node = self.tree
if node is None:
self.tree = (item, {})
return
while True:
parent, children = node
distance = self.distance_func(item, parent)
node = children.get(distance)
if node is None:
children[distance] = (item, {})
break파이썬에는 기존 BK- 트리 라이브러리가 몇 개 있었지만 (그리고 우리가 추가 한 이후로 더 많이 생각합니다), 그중 하나는 우리를 위해 작동하지 않았고 버그가 많았습니다 (ryanfox / bktree). t on PyPI (ahupp / bktree), 그래서 우리는 우리 자신을 굴 렸습니다.
다시 말하지만, Python 코드는 GitHub 및 Python 패키지 색인에서 사용할 수 있습니다. 따라서 pip 설치 pybktree 만 있으면됩니다.
출처 : https://benhoyt.com/writings/duplicate-image-detection/
이 게시물에 대해 평가 해주세요!








