이미지 텍스트 확인
Technology
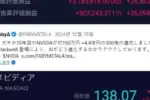
Semlconductors
AVGO
-18.36
NVDA
-17.22
AMD
TXN
MU
-7.34
0.68
-13.9
ADI
NXPI
QCOM
1.45
B씨;
1U Va
-1.6
INTC
NCHIF
2.96
Suftware Infrastructure
ORCL
-14.37
MSFT
ADBE
PLTR
-2,52
0.06
-7.01
PANWIIsNPsIIFTNT|
~7.22
0.3
CRWD
-1.72
Sorare
Dropbox으
이미지 텍스트 확인
부사장 Morgan Brown
1 먼저 배경부터 설명하켓습니다. 현재 최점단 Al 모델
올 훈련시키논 비용은 엄청나게 비싸니다.
OpenAl
Anthropic 같은 회사들은 계산에만
달러
이상울 쓰며 $4만짜리 GPU 수천 대가 필요한 대규모
이터 센터클 운영합니다 마치 공장을 운영하기 위해 발
전소 전체가 필요한 상황과 같습니다:
2 그런데 DeepSeek이l 나타나서 이렇게 말햇습니다:
‘규국국 우리라면 이걸 500만 달러로 할 _
있’결?’
그리고 말로만
것이 아니라 실제로 해넷습니다.
그들의 모델은 GPT-4와 Claude틀 많은 작업에서
하거나 대응합니다: Al 업계는 충격올 받앗습니다.
어떻게 가능햇올까요?
그들은 모든 것을 처음부터 다시 생각햇습니다.
전통적인 A논 마치 모든 숫자흘 소수점 32자리까지
것고
같습니다:
DeepSeek은 “8자리로만 기록하면 어떻까? 충분히 정확
하잡아!”라고 접근햇고 결과적으로 메모리 사용량이
5%
감소햇습니다:
그리고 그들의 “멀리 토근
시스템도 주목할 만합니
일반적인 A논 초등학생이 읽듯이 “The
cat
sat
읽습니다.
반면 DeepSeek은 문장 전체름
번에 읽습니다. 결고
2배 –
빠르
90% 수준의 정확도틀 자랑합니다:
수십
개의 단어름 처리할 때, 이런 효율성은 매우 중요
합니다
하지만 진짜 기발한 점은
전문가 시스템”올 구축햇다
것입니다:
한 거대한 시가 모든 것’ 다 알도록 만드는 대신(예:
사람이 의사 변호사; 엔지니어 역할울 모두 하는 것처럼)
DeepSeek은 필요한
우에만 전문가들올 호출하도록
설계햇습니다.
61 기존 모델은
.8조 개의 파라미터가 항상 활성화되어
야합니다:
DeepSeek은 6710억 개의 파라미터 중 단지 370억 개
성화되니다:
마치 근 팀울 운영하되 필요한 전문가만 호출하는 것과
같습니다:
기 결과는 놀랍습니다:
훈련 비용: 1억 달러
500만 달러
필요한 GPU 수: 100,000대
2,000대
API 비용: 959 절감
데이터 센터 하드웨어 대신 게이망 GPU에서도 실행 가
8/ “그런데” 누군가 말할
있습니다. “분명 단점이
켓지!”
놀라운 점은 모든 것이 오른 소스라는 것입니다:
누구나 그들의 작업올 검종할 수 있습니다. 코드는 공개
되어 있고 기술 논문은 모든 과정올 설명합니다:
마법이 아니라 단순히 매우 영리한 엔지니어랗입니다:
9/ 왜 중요한가요?
이로 인해 “대형 기술 기업만이 시틀 다률
있다”눈 기
존의 모델이 깨져습니다.
이제 수십억 달러 규모의 데이터 센터가
요하지 않습니
좋은 GPU
대만 있으면 I니다:
10/1 Nvidia에제논 두려운 이야기입니다:
그들의 비즈니스 모델은 초고가 GPU틀 90% 마진으로
판매하는 데 기반을 두고 있습니다.
하지만 모두가 일반 게이망 GPU로 시틀 돌질
앞게 된
다면
문제는 명확합니다.
11/
그리고 중요한 점은 DeepSeekol 이틀 200명 이하
팀으로 해벗다는 것입니다
한편 Meta의 팀은 DeepSeek 전체 훈련 예산보다 더 면
은 연봉올 받으며 작업흘 하고 있지만 그들의 모델은 De
epSeek만큼 쫓지 않습니다:
12/ 이논 전형적인 파괴적 학신의 이야기입니다:
기존 기업들은 기존 프로세스트 최적화하는
초점올
추는 반면 파괴적인 학신 기업들은 근본적인 접근 방식울
다시 생각합니다
DeepSeek은
많은 하드웨어들 투입하기보다 더
똑하게 접근하면 어떻까?”라고 물없습니다:
131 그 영향은 급니다:
Al 개발이 더
접근 가능해짐
경쟁이 급격히 증가
대형 기술 기업들의 “진입 장벽”이 작은 운덩이처럼
하드웨어 요구 사항(및 비용)이 급감
141 물론 OpenAI와 Anthropic 같은 대기업들이 가만
있지논 않을 것입니다:
그들은 아마도 이미 이러한 학신올 구현하고 있을 것입니
그러나 효율성의 캠프는 이제 병 밖으로 나성으미,
‘더망
은 GPU틀 투입하자”라는 접근 방식으로 돌아갈 수스 없
습니다
15/ 마지막 생각:
순간은 우리가 나중에 변곡점으로 기억할 가능성이
습니다:
마치 PC가 메인프레임올
중요하게 만들거나 플라우
컴퓨팅이 모든 것흘 바뀌던 것처럼요.
시논 더 접근 가능하고 훨씬 저럼해질 것입니다:
변화가 현재 플레이어들
어떤 영향울 미칠지논
도의 문제일 뿐입니다.
록하는
적9
PryingFan
이미지 텍스트 확인
Follow
@Prying_Fan
엔비디아 생각보다 더 심각한거구나 ..
중국이 엔비디아 저성능 집 2000개틀 이용해
고성능 집을 사용한 급의 Al 덥시크릇 제작
=>
시산업에서 중저가 침을 사용해도 충분한 성능의
A틀 만드는 것이 가능하게 된 것
=>
엔비디아 고성능 집의 필요성이 감소되어 엔비디아
의 시산업에서의 점유울이 하락
Translate post
9.40AM
1/27/25
34K Views
10
t
318
398
193
Most relevant replies
PryingFan
@Prying_Fan
5h
심치어 덥시크틀 오른소스로 풀어버려서
어떤 회사의 중저가 집(H-800)올 사용하든 덥시크
틀만드는 것이 가능해진 것이 금
01
t 10
18
Ilil 4.2K